作者:Romain Rigaux
网址:http://blog.cloudera.com/blog/2017/05/new-in-cloudera-enterprise-5-11-hue-data-search-and-tagging/
◆◆◆
自助服务商业智能和探索性分析仍然是Cloudera公司客户的主要用例。在过去一年中,我们在智能SQL编辑器Hue方面取得了一些重大进展,针对SQL开发人员提供了更为强大的用户体验,并使这些用例更加高效。
我们最新发布的Cloudera 5.11版本进一步提升了嵌入式搜索和标记的功能,从而实现更快的数据发现,并提高了书写SQL的效率。请继续阅读了解更多有关增强功能的信息,并点击demo.gethue.com试用改进后的Hue新版本。
嵌入式搜索和标记
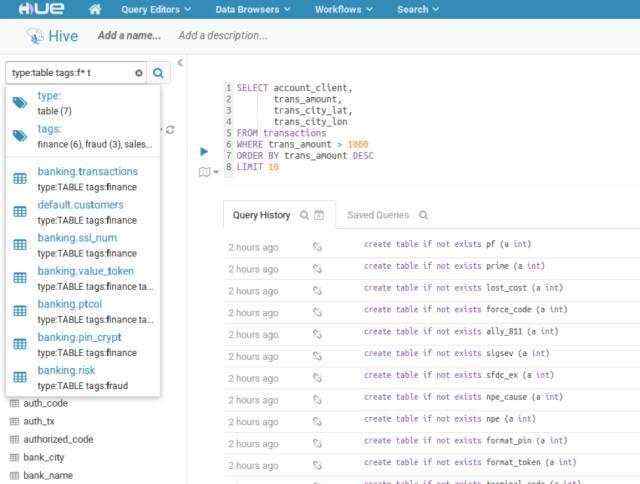
您是否曾经努力地想记住与项目相关的表名称?找到这些列或视图是否需要太长的时间?现在,Hue可以让您轻松搜索集群中所有数据库的任何表、视图或列。由于具备了搜索成千上万个表的功能,您可以快速查找与您需求相关的表,从而更快速地发现数据。
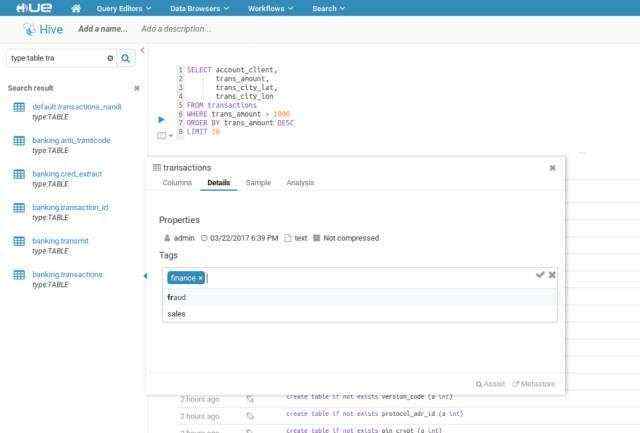
此外,您还可以使用名称标记对象以便对其进行分类,并将其分组到不同的项目。这些标签都是可搜索的,并且可以通过更简单、更直观的发现加快探索过程。
通过与Cloudera Navigator的集成,现有的标签和索引对象会自动在Hue中显示,您添加的任何其他标签都将回显在Cloudera Navigator中,并且支持熟悉的Cloudera Navigator搜索语法。
Hadoop教程:从Vimeo的Hue团队在Hue中集成Cloudera Navigator。
如需在Hue中集成Cloudera Navigator,请登录Cloudera Manager,跳转到“Hue”>“配置”,并选中两个Cloudera Navigator属性:“启用Navigator元数据服务器集成”和“启用审核收集”。
请参阅相关文档获取更详细的说明。
启用Cloudera Manager中的功能
使用方法
在Hue的SQL编辑器中将出现一个顶部搜索栏,其自动完成能力提供了facet一览表,并预先填写顶部值。按下“Enter”键可列出所有可用的对象,并且可以在示例弹出窗口中进一步打开和探索、辅助或直接进入表浏览器应用程序。
细粒度搜索
默认情况下,只返回表和视图。可使用'type:'过滤器搜索列、分区、数据库。
搜索示例:
● table:customer → 查找客户表。
● table:tax* tags:finance → 列出所有以tax开头并且标记是'finance'的表。
● owner:admin type:field usage → 列出admin用户创建的与usage匹配的所有字段。
安全性
在安全集群中,配置了Sentry,Hue可以确保结果只包含用户可以根据其Sentry权限访问的对象。这也意味着facet搜索被简化。
自动完成功能列出了当前匹配的表
具有预览和标签版本的搜索结果
SQL改进
编辑器不断改善。以下您可以阅读最近主要的改进。
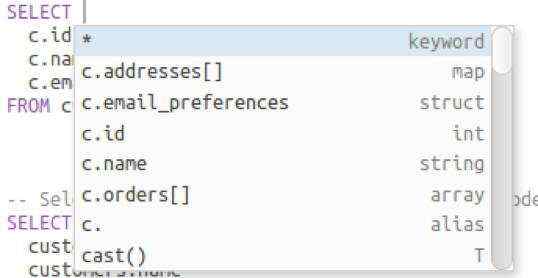
自动完成弹出式修改
像常规代码编辑器一样,自动完成分为两部分。这是为了防止在提取当前表或列的元数据时挂起,并显示更多上下文信息,例如注释、对象类型及其全名。
自动完成前
新版本中的自动完成功能
Apache Kudu主键直接表示
创建表向导
如果您在文件中创建新的SQL表时遇到困难,您将很乐意了解到,现在可以更容易地完成该操作。随着最新Hue版本的发布,您现在可以以一种特别的方式创建SQL表,从而加快自助服务分析。该向导已经修改成两个简单的步骤,并提供了更多的格式。现在用户只需要完成以下操作:
1. 选择一个文件。
2. 选择表的类型。
好,就是这样!文件可以从HDFS或S3(如果已配置)拖放、选择,并且可以自动检测格式。当执行诸如表分区、Kudu表和嵌套类型的高级功能时,该向导也可提供帮助。
请点击“阅读全文”进入微站
(更多技术干货、行业动态,请关注【微站】,不定时更新)














 京公网安备 11010802041100号
京公网安备 11010802041100号